论文地址:https://arxiv.org/pdf/1608.06993.pdf
官方实现和预训练模型:https://github.com/liuzhuang13/DenseNet
相关背景
本篇在16年8月挂到arXiv上,中了2017年CVPR,是继16年何大神的ResNet之后,第二个华人的best paper,这里有个作者本尊的talk,现场讲解。一作Gao Huang(黄高)05年北航的本科生(GPA第一),15年清华博士毕业(读了6年。。),后来在康奈尔待了3年做博后,此刻在清华作青椒,本篇是在康奈尔时的工作。二作刘壮(同等贡献)也是碉堡,现在在伯克利做博士生,之前是清华姚班的(13级),发这篇文章时还在清华,也就是说本科生。。。最近以一作的身份新发了一篇《Rethinking the Value of Network Pruning》,中了19年的ICLR,同时也是18年NIPS的best paper award。。这个世界太疯狂了,这都不是潜力股了,而是才华横溢溢的不行了。$^{[1]}$
摘要
作者说在之前的一些研究中,发现了在卷积神经网络中增加一些捷径(shorter connections,看过ResNet的应该明白)。DenseNet提出来的新的方法是,把所有层提取出来的feature map都传递到后面的层中。同时,作者提出了DenseNet的一些优势:缓解梯度消失、加强特征传递、特征复用和显著减少训练参数。他们将DenseNet应用于一些物体识别 的任务,发现在使用更少参数的情况下还能获得比其他网络更好地效果。
1. 引言
这篇文章的引言部分呢,把摘要复读了一遍。不过在第三段讲DenseNet和ResNet区别的时候,提出了一个concatenating的概念。我第一次读的时候在这个词的理解上花费了很大的功夫。其实这个concatenating 就是把上层的所有feature map直接连接在下层的feature map后面,这样的话每一层都会包含之前的所有信息。
2. 相关工作
作者说,对网络结构的探索是神经网络研究的重要工作。Highway Networks和ResNet让网络go deeper,而Inception Network能让网络go wider。而DenseNet使用的是完全不同的方法,作者强调特征复用,制造更简单有效的网络。$^{[2]}$
3. DenseNet
从这里开始,正式介绍DenseNet,是这篇文章的干货。
作者假设有一张图片$x_0$被输入到一个L层的卷积神经网络中,这个网络的每一层都使用了一种非线性变换$H_l(·)$中。这个$H_l(·)$是实现了Batch Normalization,ReLU,池化和卷积之类的操作的复合函数。假设每一层的输出为$x_l$。
3.1 ResNets
其实这一部分是和4.2对比着写的,也是为了突出DenseNet的不同之处。传统的卷积网络把第$l$层的输出作为$l+1$层的输入。ResNet增加了一个跳跃连接,就相当于$x_l = H_l(x_{l-1}) + x_{l-1}$ 。作者这么说,其实就是相当于用自定义的$H_l(·)$函数来解释一些下ResNet里面的那个$a_{l+2} = g(z_{l+2} + a_l)$。也就是说,在ResNet中,复合函数$H_l(·)$就是一个Conv+Pool+ReLu+Conv+Pool。
3.2 Dense connectivityxw
这一部分是作者提出DenseNet的连接方式,我们看作者提出的式子:
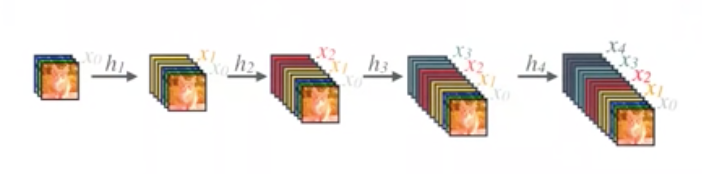
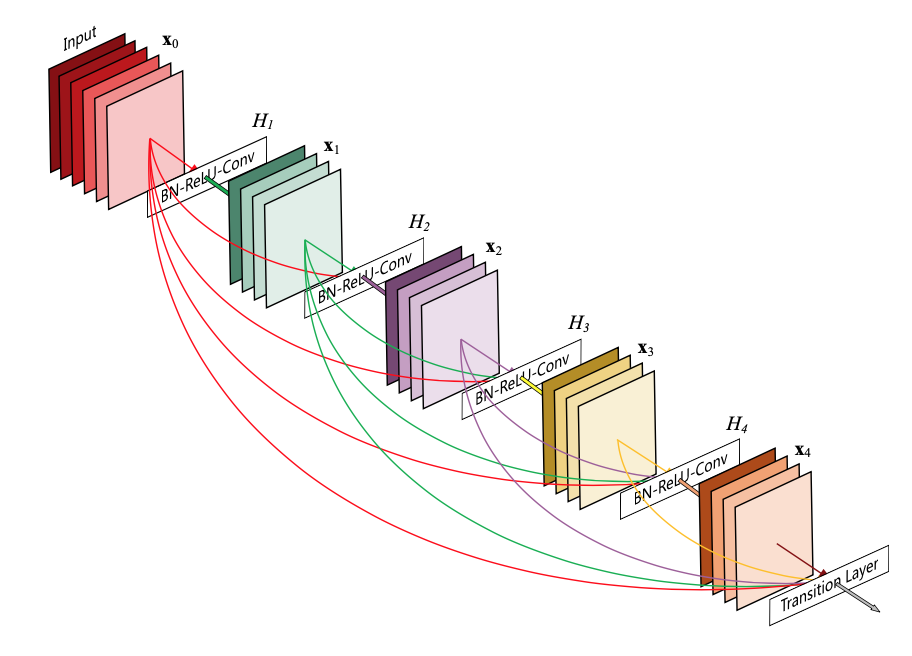
先不管$H_l(·)$的具体实现,这个式子可以说明每一层的特征图都会包含之前所有特征。同时,观察图3.2.1和图3.2.2,由于DenseNet强调特征复用,所以他的每一个卷积层能够变得更“slim”, 这也是DenseNet所用的参数比较少的一个原因。对于图3.2.3,我们可以发现,对于$L$层的网络,DenseNet总共需要$\frac{L(L+1)}{2}$次连接。
3.3 Composite function
这个部分作者对复合函数进行了非常简短的说明,$H_l(x) = BN - ReLU - Conv$,也就是先做Batch Normalization,再做ReLU最后做卷积。这里作者没有说明为什么先用激活函数再卷积,但是可能和Identity mappings in deep residual networks这篇文章有关系。
3.4 Pooling layers
在式1中,要把$x_0, x_1, x_2, \dots, x_{l-1}$这些特征连接起来,需要他们有相同的维度。所以说不能直接在Conv后面接池化。为了在网络中使用池化,作者把网络划分成多个dense block。如图3.2.3即为一个denseblock。而在dense block之间,作者提出了transition层,用于做卷积和池化操作。transition层包括了一个Batch Normaliztion,一个1x1卷积和一个2x2 average pooling。

3.5 Growth rate
如果说,每个$H_l$输出了k张feature map,那么在第$l$层,总共会有$k_0 + k × (l − 1)$个feature map。作者把这里的$k$定义为增长率,在后文的实现部分,作者在实验部分说明了即使用很小的增长率也可以获得STOA的效果。
3.6 Bottleneck layers
瓶颈层是在3x3卷积之前加入1x1的卷积,作者发现使用瓶颈层在DenseNet上尤其有效。加入瓶颈层以后复合函数就变成了$H_l(x) = BN-ReLU-Conv(1× 1)-BN-ReLU-Conv(3×3) $。运用了瓶颈层的DenseNet就叫DenseNet-B。
3.7 Compression
这里所谓的压缩,就是在transition层中,减少feature map的数量,从而达到进一步“ensilm”模型的效果。作者定义了压缩因子$\theta$,如果说原本有m个feature map,那么只保留$\lfloor \theta*x \rfloor$个feature map。运用了Compression的DenseNet就叫DenseNet-C,如果即使用了瓶颈层,又用了Compression,就是DenseNet-BC了。
后续
文章后面是一些实验,不再详细说明了。在这篇博客里面,有一些不完美的地方,比如3.3中,先ReLU再Conv的原因、3.4中AP和MP的选择、3.7中compression的实现方法等等。可能作进一步了解以后可以更新本篇。
参考文献
[1] 论文阅读 | CVPR2017(Best Paper) | Densely Connected Convolutional Networks, https://www.jianshu.com/p/cced2e8378bf, 2019.3
[2] DenseNet 论文阅读笔记, https://www.cnblogs.com/zhhfan/p/10187634.html, 2018.12


